一直以来,图书馆自动化领域遵循着稳步发展的原则,在功能和设计上变化甚微。但与几十年前相比,图书馆已经发生巨大的改变。网络和计算机技术的快速发展,颠覆了传统的信息的生产、传播与交流的方式,拓展了信息的载体的形式,导致图书馆收藏格局和服务形式的转变。近年来,Web 2.0技术和理念的盛行,促进用户行为的变化,越来越多的读者通过图书馆以外的渠道获取信息,在网络上进行信息交换和协同合作。用户需求和期望的改变,经济的变化,技术的发展,以及图书馆之外全球信息服务环境给图书馆带来日益增加的压力,将图书馆置于变革的激流之中,使其必须重新认识和组织核心任务,这就给图书馆自动化系统提出了新的要求。
目前图书馆自动化行业正经历着巨大的过渡和动荡。自动化厂商纷纷合并,强强联合,导致一些现有系统的消亡。选择的减少,经费的限制,给那些作为备选的开放资源,以及在这些开放资源基础上提供改进、技术支持等服务的新公司打开了大门。专业厂商提供的自动化系统已经不再是图书馆的惟一选择,开源产品逐渐进入人们的视野。最初,一些公共图书馆进行尝试,随即许多学术和专业图书馆也开始选择开源产品。
在这样的一个环境之下,本文对商业自动化系统与开源的系统进行比较分析,总结其优势与不足,为相关人员提供一定的参考。为此,本文选取了两个比较有代表性的自动化系统进行比较,一个是开源图书馆自动化系统Koha(版本3.2),另一个是商业自动化系统Aleph 500(版本18)。
两种软件的起源与应用状况
Koha集成图书馆自动化系统
Koha系统产生于1999年,被业内人士认为是全球第一个自动化开源软件,由新西兰的KatipoCommunications公司替赫罗范努瓦图书馆理事会(Horowhenua LibraryTrust,HLT)开发。Koha系统集成了图书馆的传统业务流程,包括采购、编目、流通、OPAC、读者管理。同时还为用户提供个性化的定制机制。目前Koha系统主要安装在公共图书馆、个人和高校图书馆的部门,在美国的图书馆组织已经有300多家采用此系统。在采用Koha图书馆管理系统的图书馆里,美国俄亥俄州阿森斯的纳尔逊维尔公共图书馆是规模最大的,拥有馆藏量250,000(书和书资料),每年流通量为650,000。
Aleph 500自动化系统
Aleph500是以色列Ex Libris公司开发的一套图书馆自动化集成管理计算机软件系统,最早由Ex Libris公司与希伯来大学于1980年合作开发,历经数个版本的研发与改进及30年的市场考验。目前全世界有1250多套Aleph系统安装在51个国家和地区的图书馆及多馆联合组织内,支持超过20种以上的语言接口。Aleph 500系统的软件架构十分先进,个性化的设计理念也深受图书馆界的肯定。其提供的良好的客服系统、教育培训和技术支持,取得了美国哈佛大学、麻省理工、纽约州立大学、明尼苏达州图书馆联盟等全世界顶尖学术单位的采用。2000年由北京师范大学图书馆引进并汉化,目前在国内已经被国家图书馆、复旦大学、上海交通大学在内的24家图书馆采用。
系统架构的对比
良好的架构对于图书馆集成管理系统的性能、功能来说十分重要。Aleph与Koha系统架构对比情况见表1。
表1 Aleph与Koha系统架构对比
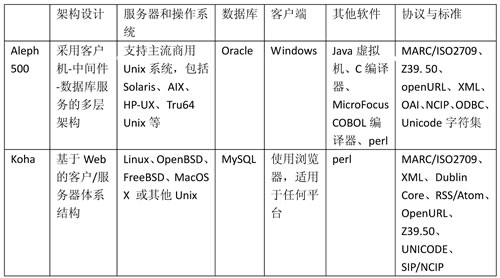
从架构上看,Aleph 500系统与Koha在设计上有很大的不同。Aleph 500的架构设计采用的是多层架构,具体来说包含有3个大层和5个细层(如图1所示)。
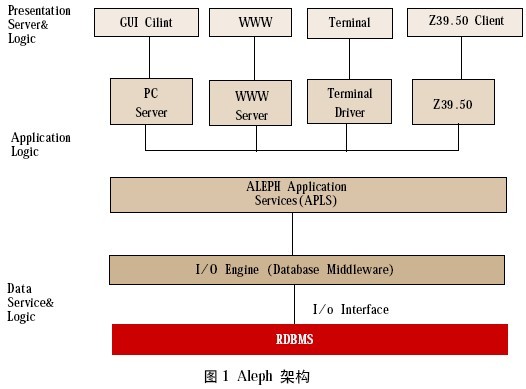
三个大层为表现逻辑层、应用逻辑层和数据逻辑层。其中,应用逻辑层包含用户服务和API接口两个细层。前者为逻辑层提供服务;后者是Aleph的核心应用,以便为不同的客户端提供服务。而数据逻辑层也分为引擎和数据库两个细层,前者把抽象的数据宏观操作转换成一组数据库命令;后者就是底层数据库管理系统。这三个层次功能分工明确,层间的访问接口严格遵循层次结构,具有很强的可靠性和可用性。
同时,Aleph体系结构支持灵活的配置和扩展。Aleph系统所具有模块化的功能组件和全面的表驱动参数配置模式,可以方便地增减组件、控制和维护系统的各项功能,以及各种显示界面,根据本馆业务进行定制。Aleph 500提供了标准的开发接口,例如X-Service、SIP2、SQL等,可以在此基础上进行二次开发,以扩展系统的功能。其中,X-Service API提供了开发的接口,使得外部系统能够通过标准的XML 接口与Aleph系统进行交互,从而使得用户可以自行开发个性化服务系统,提供PDA、手机等终端设备的接入功能。
Koha系统的架构主要基于Web的B/S(浏览器/服务器)体系结构,通过Web浏览器来接入系统,如图2所示。其核心是Perl脚本,包括OPAC系统、Intranet系统、Daemons系统,以及DB系统的四个组成部分。OPAC系统面向读者,基于标准的WWW技术开发,如X H T M L 、C S S 和JavaScript。Intranet系统是馆员用以处理后台事务与前台操作的接口,使用浏览器来登录系统进行图书馆基本业务的操作。如馆员用户的登录、资源采购、流通等。Daemons系统是为利用Z39.50协议查询资源的用户提供到Z39.50服务器的连接。DB系统为数据库的存取操作提供支持。整体的架构以Apache HTTP 服务器与Perl脚本作为中间件,系统的层次功能较为分明、可靠。同时Koha支持SIP/NCIP等标准协议,使得系统具有较强的可扩展性。
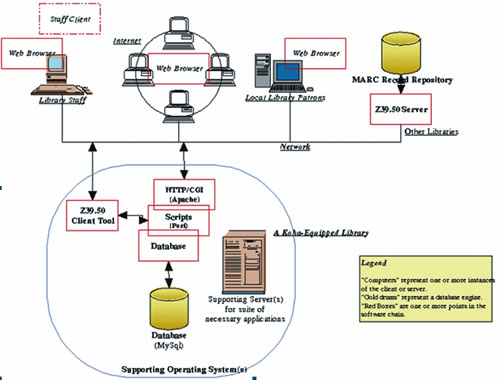
图2 Koha架构
在客户端设计上,Aleph500采用的是C/S的模式,而Koha采用的是B/S的方式。前者的主要缺点在于需要安装客户端程序,要考虑客户端的平台,不能够实现快速部署安装和配置,升级较为麻烦。而后者简化了客户端,减轻了系统维护与升级的成本和工作量,相对来说更加方便、快捷和高效,同时也更符合目前网络环境的要求。
此外,由于Aleph 500这款软件在服务器端需要安装上C 编译器、MicroFocusCOBOL编译器等辅助软件,在客户端还需要安装Java虚拟机,因此,相对来说比较复杂。而Koha在服务器端安装上perl编译器,在客户端只需要有Web浏览器即可运行,较为简单。
模块功能的考察
对于系统模块的考察,主要是通过对比各个模块的基本业务功能是否完备、能够满足业务需求。目前两个系统都提供全面的图书馆管理系统的功能,包括流通、编目、采购、期刊、公共检索平台等基本业务模块,但各个模块的具体功能还存在差异。
公共检索平台功能
两个系统的Web OPAC都能向读者提供题名、作者、关键词、索书号等多种途径的简单检索、高级检索,以及布尔检索功能。读者能够在网上进行图书预约、续借、账户信息查询和管理、虚拟电子书架的管理。两者的OPAC都能提供Web 2.0的功能,包括封面、文摘、目次、网上书评、评级、标签、检索词提示等。其中,Aleph的相关封面、书评等信息是抓取豆瓣上的内容,Koha则抓取Amazon上的内容。同时还能实现利用Amazon的数据来推荐其他相关产品。
此外,Koha利用Ajax技术实现动态查询,即在用户输入检索词的同时,返回包括封面、书名、评分等信息的结果集;能通过RSS来订阅新书通报等信息;整合Zetero书目管理软件,能够将在Koha的OPAC中检索到的书目记录加入Zetero中进行管理和使用。
Aleph 500的Web OPAC的Web2.0功能是由ExLibris公司中国大陆办事处的相关人员进行开发完成的。而Koha的OPAC功能是由公司以外的第三者在软件模块的基础上自行开发完成,更具有灵活性,在功能上可以通过本馆的要求进行配置和增减,在细节上更为人性化。
流通模块
两个系统流通模块都包括日常借还书、预约、续借、脱机流通、现金管理、阅览室管理功能、通知单寄送以及读者管理工作。都能够配置分馆,根据用户权限、馆藏类型、馆址等参数来配置流通政策。同时,两者都能够进行读者数据的批量导入,这样就大大简化高校图书馆新建大量读者的工作量。在实现方式上,Aleph 500是通过后台脚本导入读者,而Koha是利用可视化的Web界面进行操作,且支持CVS格式导入,相对来说更加直观、便捷。
采访模块
两个系统都提供书商管理、货币管理、预算管理、订单管理和检索等基本功能。
相比较而言,Koha缺少发票管理的功能。在数据批量导入和订单处理方面,Aleph 500能够实现定购数据(书目数据、书商、金额、定购数量等)批量导入系统,并执行查重,生成定购清单。而在Koha文档中未体现批量导入的功能,需要订单单条地增加。
在预算的管理上,Koha中的预算超额并不会影响订单的发订,只会进行提醒。而Aleph 500中通过基于Web的图书采访拟订与荐购系统(APSM)来发订单时,并不会进行预算的核查,也不会提醒预算使用的情况。同时,两者都提供OPAC上读者荐购的功能。Aleph 500会在OPAC上的读者中心中反映出荐购的进度,而Koha可由电子邮件告知读者荐购情况以及到书情况。
编目模块
在编目模块中,Aleph 500作为成熟的系统,功能较为强大,提供编目所需要的基本功能。例如支持Unicode、多MARC格式、多途径检索、编目模板设定、MARC编辑、规范控制、馆藏维护、转入转出ISO-2709格式数据、Z39. 5联机编目、标签打印等。在此基础上还提供某些字段自动生成、数据校验、在编数据自动本地备份、数据状态变化的历史记载等实用自动程序,提高编目工作效率和书目数据的质量。此外,Aleph500 还提供数字资产管理模块,实现为书目记录链接相关的数字对象(图片、音像、电子文档等)及其使用权限管理的功能。同时,实现了与CALIS联机编目系统的集成,提供完整的书目、馆藏上传下载功能。
相对而言,Koha的编目模块较为简单,只提供编目的模板设定、MARC编辑、字段检验、多途径检索、复本管理、转入转出ISO-2709格式,以及以Z39.50方式联机使用多个Z39.50 服务器下载数据,基本能够实现编目的要求,但是在效率上和质量控制上有所欠缺。
期刊模块
两个系统期刊模块都提供期刊编目、创建订单记录、期刊控制和预测、设置出版频率、登到、催缺等功能,能够满足图书馆管理期刊方面的日常工作需求。此外,Koha可根据评论订阅期刊,追踪期刊的到馆率。而Aleph的报刊采访拟订系统(APSM)提供相对较强大和便捷的功能来实现期刊的新订和续订工作。
统计功能
Koha提供很多统计功能,包括采访统计、读者统计、目录统计、流通统计、期刊统计、最常借出的读者、最常借出的馆藏、未曾借出的读者、未曾借出的馆藏、依馆藏型式统计、遗失馆藏、平均借出时间等,此外还能自行设置统计的模块、格式、字段、排序方式等内容来增加和修改个性化报表。
而Aleph 500的统计功能是以服务的形式来提供的,自动自带的统计服务较少,但可由工作人员自行开发相应的统计服务以满足个性化的需求。
技术服务和支持的差异
经过了多年的本地化开发,Aleph 500用户界面全部支持中文,全面支持处理汉语拼音系统。中文实现自动切分,支持中文检索和排序,全面支持CNMARC。同时,ExLibris公司网站上具有完备的在线技术资料,且在中国大陆设立有办事处,能够为中国用户提供及时有效的本地化技术支持和服务。
Koha是开源软件,用户通常需要自己在相关网站中下载安装与操作文档。Koha的网站上提供较为全面的文档,包括安装文档、操作文档等。此外还提供开发者社区供使用的图书馆、开发人员等进行需求讨论,以及技术支持和开发交流。除了Koha的开发网站之外,美国LibLime等公司为Koha提供商业的技术支持、软件安装及托管服务。
在中文本地化方面,台湾毛庆祯教授等人于2005年开始进行Koha的中文繁体化的过程,实现界面的中文繁体开发,并添加台湾CMARC的支持。此后,他们投入很多力量实现对CNMARC的支持,并提供简体中文界面。目前中国沁县图书馆使用的Koha系统正是由毛庆祯教授等人安装并维护的。此外,毛庆祯教授等人于2005年9月成立了Koha中文的讨论组,并创立Koha中文的WiKi网站,以中文回答Koha客户的问题,为中文Koha的使用者提供技术支持。
通过以上比较和分析,可以看出与商业的Aleph 500系统相比,Koha的确存在一些不足,但是作为一款免费的开源软件,Koha在功能上基本成熟,在细节上的处理较为人性化且具有较大的扩展空间,无须局限于供应商所提供的功能,可以灵活配置,且不受使用人数和使用方式上的限制,完全和彻底地控制自己的数据和系统。技术力量较强的馆还能通过分析源代码,在此基础上进行修改和功能的增强,以便于更加贴近自身的需求。同时也应该看到,开源软件的使用还存在着一些潜在的问题,例如技术支持和馆员培训的问题,安装和配置方面需要高素质技术人员的问题,以及中文本地化的问题。可见,对于开源的图书馆集成系统的使用还需要有更多的关注和投入,帮助其不断完善,更加的安全、稳定、易用,以符合图书馆的需求。(作者单位为首都师范大学图书馆)
转载自:http://www.edu.cn/ruan_jian_ying_yong_1720/20120814/t20120814_827957_2.shtml
